
Facebook Groupify
This is a side project I’ve been working on occasionally in my spare time. Facebook Groups are often a wonderful place for finding new music. There’s many niche genre/location specific music groups that are goldmines. I regularly go through the process of opening a music group on Facebook, scrolling through the page and clicking on posts that link to Youtube, Spotify, Soundcloud, Bandcamp and other streaming sites. I give the songs a listen and then if I like it I add it to my Spotify. It would be nice if I could just have all of these songs already in Spotify and just listen to them with no interruption of having to click on the next link.
So I’ve created what I dub as FacebookGroupify (Facebook Groups + Spotify) to bridge this gap.
What is it?
A Facebook group and Spotify Playlist is specified by the user. FacebookGroupify retrieves Youtube and Spotify links that have been posted into the Facebook Group. If the song exists on Spotify then it’s added to the Playlist. This is repeated daily to continuously keep the playlists fresh.
How Does it Work?
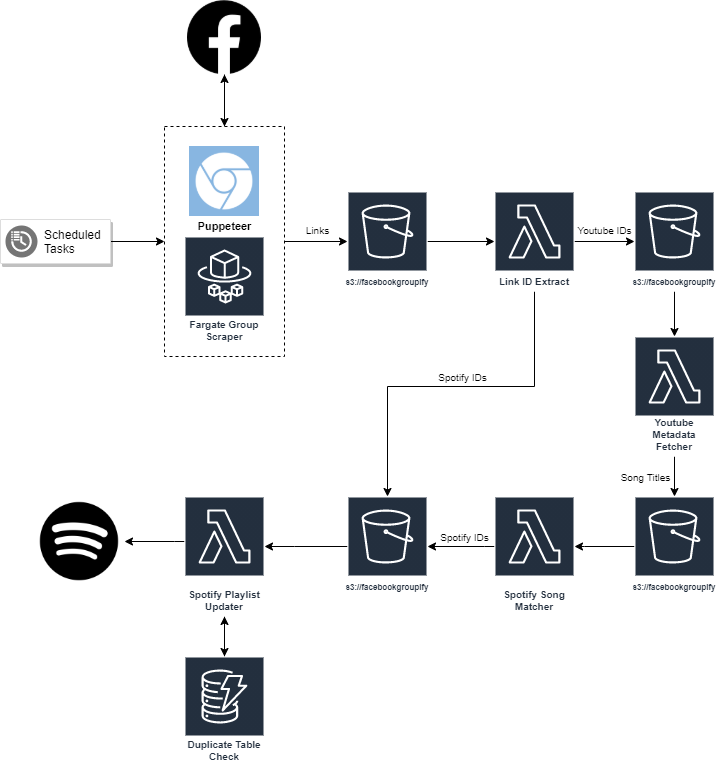
Facebook Scraper
Puppeteer is used to load Facebook in a headless browser and login using username+password or a saved session from a previous login. It navigates to the Facebook group and endlessly scrolls until it either reaches the end of the page or has exceeded a time limit. All links are scraped from the page and saved to S3.
Link ID Extract
A Lambda is triggered which loads the scraped links and extracts Youtube, Spotify, Soundcloud and Bandcamp IDs from the links which are then saved to S3.
Youtube Metadata Fetcher
Another Lambda is triggered and this time it fetches metadata about the Youtube IDs. The most valuable piece of information here is the Youtube title is a key part which is used later. The metadata is saved to S3.
Spotify Song Matcher
The metadata saved to S3 triggers this Lambda which attempts to match song titles found with songs that exist on Spotify. Not every song exists on Spotify and the Youtube titles sometimes differ from the Spotify titles. The song matcher cleans the titles to remove irrelevant text seen on Youtube songs such as “(Official Video)” or “(Music Video)”. Titles are used to search for Songs on Spotify and the similarity of the two titles is calculated. The best matching Spotify songs have their IDs saved to S3. The similarity must exceed a set threshold.
Spotify Playlist Updater
The Spotify IDs saved to S3 trigger a lambda that inserts the songs into the specified playlist. Spotify’s API does not provide functionality to prevent duplicates so instead the app saves the key value pair of ID -> Playlist ID to DynamoDB which allows us to prevent inserting the song into the same playlist again in the future.
What’s next?
-
The biggest bottleneck is the Facebook scraper. To scrape new Facebook groups I personally must be a member of the group. My Facebook account is a single point of failure in the system. If I get locked out then the application fails. The joining of a Facebook Group could be automated through Chromium but it is not a desirable way to do this. Web crawling/scraping is fidgety and websites change often meaning that it can not reliably be considered a repeatable method. Facebook does have an API which allows group administrators to access group posts. This looks to be the most promising method. Solving the Facebook scraper using the API would allow the application to move towards a self-serving manner where users do not need technical knowledge to run the app.
-
Improve the quality of the project (there’s a lack of testing as this started out as a hack) so other people can confidently contribute.
-
Add Soundcloud and Bandcamp integration. All of the Facebook music groups I am a member of are dominated by Youtube links however there are many gems often posted to other platforms. I’d like to see all content being collected and processed.
Keep up with the project here.
Do you have a Facebook Group that you’d love to see in a Spotify playlist updated daily? If so get in touch and I’ll get it running.